Kakade에 의한 내용 : http://www.gatsby.ucl.ac.kr
I. Natural Gradient
## NG란?
- Natural Gradient에서는 Policy가 리만매니폴드(manifold)를 따른다는 가정을 하고 이에 근거하여 계산한 Gradient를 말한다.
- 리만 공간(리만매니폴드)을 기반으로 하여 거리를 계산하는 방법을 Natural Gradient라고 한다.
## 매니폴드
아래 그림에서와 같은 점들을 아우르는 subspace를 의미한다.

## 리만매니폴드(Rimannian Manifold)
매니폴드가 각지지 않고, 미분 가능하게 부드럽게 곡률을 가진 면을 의미한다.
Manifold중에서 부드럽게 생긴, 미분 가능한 Manifold를 말한다.
유클리디안에서의 이차미분 = 리만공간에서의 일차미분
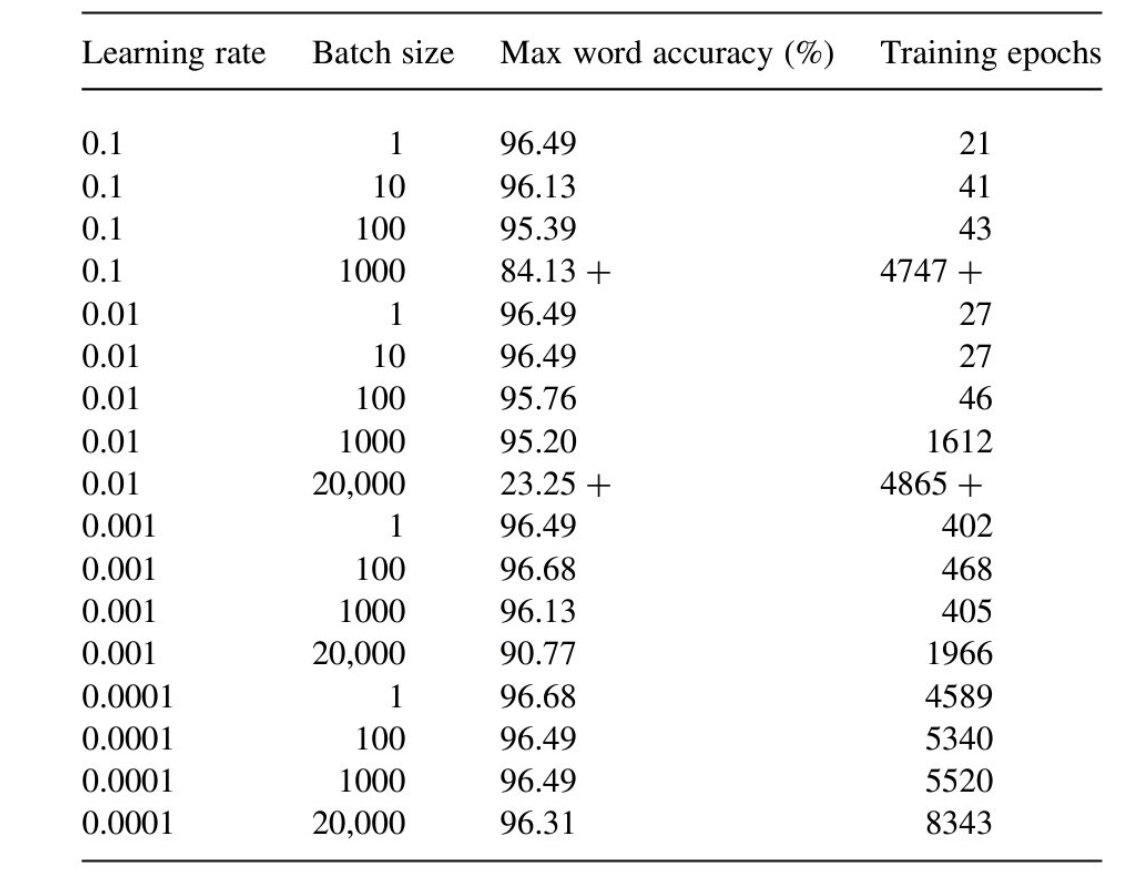
## RL에서 natural gradient의 유용성
논문 그림에서와 같이 natural policy gradints의 경우 보다 좋은 성능을 보여주고 있음
일반적인 gradient대신에 natural gradient가 학습 성능이 좋다는 것을 실험으로 입증함

## Gradient대신 NG이 Steepest Descent Direction을 갖는이유
- Neural Network 에서 가장 경사가 급한 방향은 Natural Gradient인 경우가 된다.
신경망을 사용할 경우 Gradient가 Steepest Direction이 아닌 경우가 많다.
신경망의 Parameter Space가 우리가 보통 생각하는 직선으로 쭉쭉 뻗어있는 Eucidean Space가 아니다.
좀더 일반적으로는 구의 표면과 같이 휘어져있는 공간인 리만공간(Riemannian Space)으로 표현할 수 있다. 이러한 공간에서는 Natural Gradient가 Steepest Direction이 된다.
## NPG의 한계
Natural Policy Gradient만으로 업데이트하면 policy의 improvement를 반드시 보장할 수는 없다.
- Policy의 Improvement를 보장하려면 line search를 사용해야만 한다.
## FIM(Fisher Information Manifold)
- 리만 공간에 적용 가능한 Positive Definite Matrix 중 하나이다.
Manifold모양이 계속 바뀔때마다 같아야 할 θ간의 거리가 달라져(variant) 버리면Policy 최적화에 어려움을 겪을 수 있으니 이를 Invariant하게 만드는게 좋은데 해결 방법은 Fisher Information Matrix를 G(θ)로 쓰는 것이다.
- NPG에서의 steepest descent direction은 아래와 같다.

위식의 해석은 FIM이라는 Positive-Definite Matrix를 사용하여 리만공간을 고려한 방향 및 크기로 목표함수를 업데이트 한다는 것을 의미한다.
## Positive Definite Matrix이란 무엇인가?
- 양의 정부호 행렬
-> Symmetric Matrix ⊃ Positive Definite Matrix
-> 대칭행렬은 실수인 고유값들을 갖는다.
양의 정부호 행렬도 마찬가지로 실수인 고유값들을 갖는데
더 나아가서 고유값들이 모두 양수이다.
- 함수 f(x,y)는 점(0,0)을 제외하고는 모두 다 0보다 큰 값을 갖는경우,
이러한 함수를 양의 정부호(positive definite)라고 한다.
함수값들이 정류점을 제외하고는 양수로 한정되어 있기 때문이다.
양의 정부호(positive definite)인 경우에는 극소점을 갖는다. 이와는 달리 음의 정부호(Negative Definite)인 경우에는 극대점을 갖는다.
## NPG를 배우기 전에 매니폴드를 배우는 이유?
- Natural Gradient Method는 어떤 파라미터 공간에서의 steepest descent direction을 강조하기 때문에 신경망 학습에 매우 중요한 방법이 된다. 앞에서도 언급하였듯이 신경망 학습에서 Gradient 찾아낸다고 하더라도 제대로 학습이 진행되지 않는 경우가 있다.
왜냐하면 파라미터 공간이 Euclidean 공간이 아니라 리만 매니폴드 공간이기 때문이라고 할 수 있다.
다시한번 언급하지만 리만 매니폴드는 매니폴드가 각지지 않고 미분 가능하게 부드럽게 곡률을 가진 면이라고 생각하면 된다.
## 폴리시의 이해
- 폴리시는 파라미터(θ)로 이루어진 함수이다.
- 폴리시는 몇차 함수일까? 보통 굉장히 고차원이고 우리가 어릿속으로 떠올릴 수 있는 차원이 아니다.
## 폴리시의 차원
- 강화학습에서 policy는 고차원일 가능성이 높음(다차원 벡터)
- 최적의 폴리시를 찾는 과정에서 대상 폴리시는 조금씩 변함 -> 공간에 흩뿌려진 형태일 가능성이 높음
- 폴리시의 함수를 시각하하기 위해 편의상 3차원으로 떠올려보자.
- 3차원으로 볼 경우 다음 그림과 같을 것이며 각각의 점은 폴리시라고 할 수 있다.

매니폴드는 조금씩 점을 이동하면서 유의미한 변화가 나타남을 의미한다.

## 강화학습의 목표
- 성능을 최대화하는 θ를 찾는 것
- 보상을 최대화하는 것
- J(θ) : 성능(목표함수)
- ▽J(θ) -> θ학습 -> J(θ) 최대화
## 매니폴드란?
- 공간에 흩뿌려진 많은 점들을 아우르는 subspace공간을 의미함
- 많이 접힌 것, 많이 접히면서 점들을 아우르는 것
-> 2d로 만들어 버리면 차원축소(dimensionally reduction)가 됨
- 이렇게 접힌 것을 쫙쫙 펴서 2d로 만들어 버리면 dimensionally reduction이 된다.
-> 물론 완벽한 2d가 되지 않을 수 있지만 국소적으로는 2d가 된다.
## 매니폴드의 필요성
- 고차원 파라미터를 저차원에서 생각할 수 있음
-> 차원을 축소하면 점들 사이의 상관관계를 더욱 잘 알 수 있음
## 매니폴드와 NPG
- NPG는 어떤 파라미터 공간(리만 매니폴드)에서의 가장 하강경사가 급한 방향을 중요하게 생각함
- 리만매니폴드란? 매니폴드가 각지지 않고 미분가능하게 부드러운 곡률을 가진 면이라고 한다.
## 매니폴드의 이해
- 매니폴드를 고려하지 않고 B에서 A1의 거리와 A2의 거리를 비교해보면
유클리드 공간에서의 거리는 B에서 A1까지가 더 가깝다고 여길 것이다.
그러나 리만 공간(매니폴드)을 고려하면 B에서 A2까지가 더 가깝다.
-> 리만공간에서 첫번째 이동한 결과 : 폴리시(A1) = 폴리시(B + 1000)
-> 리만공간에서 두번째 이동한 결과 : 폴리시(A2) = 폴리시(B + 10)
- 기존 차원(유클리디안 공간 해석)에서 볼 경우 B와 A1이 보다 가까운 거리일수있지만
기존과 다른 매니폴드측면(리만 공간 해석)에서 볼 경우 B와 A2가 보다 더 가까운 거리가 된다.
## Covariant(공변량)의 이해
- B와 A1보다 B와 A2가 더 Covariant하다고 할 수 있다.
-> 왜냐하면 리만 매니폴드에서는 B기준으로 볼 때, A2가 A1보다 더 가깝기 때문이다.
-> 리만공간(매니폴드)상에서는 눈으로 보이는 것이 다가 아니다.
## 바람직한 Policy 변경 방법
- Policy(B)에서 Policy Gradient를 통해, Policy(B+delta B)로 간것이 Policy(A1)이라면
Policy가 너무 지나치게 바뀜을 느낄 수 있다.
- 따라서 delta B에 0.0001과 같이 작은 수의 스텝 사이즈를 더하여 조금씩 변하게 하여
Policy(B) -> Policy(A2) -> Policy(A1)으로 변경되도록 하는 것이 보다 바람직하다.

## 매니폴드와 폴리시 그레디언트
- 기준점 B에서 폴리시 그레디언트를 통해 이동한다고 하자.
- 이 경우 A1과 A2가 상대적으로 보다 covariant하다고 정의할 수 있다.
-> 좌측그림으로 판단(유클리드 공간으로 해석)할 때 B기준으로 A1이 더 가깝다고 판단할 수 있으나
매니폴드를 전개하여 판단(리만매니폴드 베이스로 해석)할 때 B기준으로 A2가 더 가깝다고 판단할 수 있다.
-> policy(B+delta B)로 간 것이 Policy(A1)보다는 Policy(A2)가 보다 더 유의미하다고 할 수 있다.
## 리만 매니폴드의 개념
1. 리만매니폴드의 정의
- 미분가능한 매니폴드를 리만 매니폴드라고 정의한다.
2. 리만공간과 유클리디안 공간
- 유클리디안 공간에서의 이차미분(곡률) = 리만 공간에서의 일차미분(Natural Gradient)
- 유클리디안 공간에서 보면 곡률을 따르는 일직선은 곡선으로 보인다.
- 유클리디안 공간에서의 이차미분 = 리만공간에서의 일차미분
-> Natural Gradient에서는 Policy가 리만 manifold를 따른다는 가정을 하고
이에 근거하여 Gradient를 계산하며 이 결과를 Natural Gradient라고 한다.

III. 요약
## 결론
PPO가 나온 이유를 알기 위해서는 NPG를 알아야 한다.
NPG(2001) -> TRPO(2015) -> PPO(2017)
Natural Gradient에서는 Policy가 리만 매니폴드를 따른다는 가정을 한다.
Riemannian Manifold(리만매니폴드)란? 매니폴드중에서도 매니폴드가 각지지 않고 부드럽게 생긴, 미분 가능한 매니폴드이다.
Natural Policy Gradient는 리만공간(굽은공간)에서의 일차미분(일차근사)을 이용하여 Gradient를 계산하고 이를 이용하여 Policy를 업데이트한다.



























![image_thumb[8]](http://sabumjung.files.wordpress.com/2021/03/image_thumb8.png "image_thumb[8]")




![clip_image001[5]](http://sabumjung.files.wordpress.com/2021/03/clip_image0015.png "clip_image001[5]")
![clip_image001[7]](http://sabumjung.files.wordpress.com/2021/03/clip_image0017.png "clip_image001[7]")



![[가평] 카라반캠핑농원](https://static.coupangcdn.com/image/affiliate/banner/d1eeb6efbdc69377818f53be65c09838@2x.jpg)

![[내륙] [내륙항공권모음] 김포↔부산,광주,여수,포항,대구 ◈특가◈ 편도항공권](https://static.coupangcdn.com/image/affiliate/banner/4c946f3bcd43e1378d34f63fdc6434c3@2x.jpg)
![clip_image007_thumb[1]](http://sabumjung.files.wordpress.com/2021/03/clip_image007_thumb1.png "clip_image007_thumb[1]")
![clip_image008_thumb[1]](http://sabumjung.files.wordpress.com/2021/03/clip_image008_thumb1.png "clip_image008_thumb[1]")






{kind=link}